Claude Code Deep Dive Guide: Mastering Every Feature from Beginner to Expert
Original article: https://mp.weixin.qq.com/s/TUXrRq1s1T4b6i2o-M7BeA
ThinkInAI ThinkInAI Community 2025-11-11 08:18
As a hobbyist, I run it several times a week in VMs for side projects, often using the --dangerously-skip-permissions flag to quickly implement ideas in my head. Professionally, part of my team's job is building AI-IDE rules and tools for our engineering team, tools that consume billions of tokens per month just for code generation.
The CLI agent space is getting crowded, and between Claude Code, Gemini CLI, Cursor, and Codex CLI, it feels like the real competition is between Anthropic and OpenAI. But honestly, when I talk to other developers, their choices often come down to seemingly superficial things—a "lucky" feature implementation, or they just like how the system prompt "feels." At this stage, these tools are all pretty good. I also think people often over-index on output style or UI. For me, something like "You're absolutely right!" sycophancy isn't a bug worth noting; it's just a signal that you're over-involved. Overall, my goal is "fire and forget"—delegate tasks, set context, and let it do its thing. I judge tools by the final PR, not how it got there.
After sticking with Claude Code for the past few months, this post is my reflection on Claude Code's entire ecosystem. We'll cover nearly every feature I use (and equally important, those I don't), from basic CLAUDE.md files and custom slash commands, to powerful Subagents, Hooks, and GitHub Actions. This post is long, and I recommend treating it as a reference rather than reading it in one sitting.
CLAUDE.md Files
To use Claude Code effectively, the single most important file in your codebase is the CLAUDE.md at the root. This file is the agent's "constitution," the primary source of truth for how your specific repository works.
How you treat this file depends on context. For my hobby projects, I let Claude write whatever it wants in there.
For my professional work, our monorepo's CLAUDE.md is strictly maintained and currently 13KB (I can easily see it growing to 25KB).
It only documents tools and APIs used by 30% (arbitrary threshold) or more of engineers (otherwise tools are documented in product or library-specific markdown files)
We've even started allocating an effective max token count for each internal tool's documentation, almost like "selling ad space" to the team. If you can't explain your tool concisely, it's not ready for CLAUDE.md.
Tips and Common Anti-patterns
Over time, we've developed a strong, opinionated philosophy for writing effective CLAUDE.md.
Start with guardrails, not manuals. Your CLAUDE.md should start small and document based on where Claude went wrong.
Don't @-file reference docs. If you have extensive documentation elsewhere, it's tempting to @-mention those files in CLAUDE.md. This bloats the context window by embedding the entire file on every run. But if you just mention the path, Claude often ignores it. You have to sell the agent on why and when to read the file. "For complex... usage or if you encounter FooBarError, see path/to/docs.md for advanced troubleshooting steps."
Don't just say "never". Avoid negative-only constraints like "never use the --foo-bar flag." The agent gets stuck when it thinks it has to use that flag. Always provide alternatives.
Use CLAUDE.md as a forcing function. If your CLI commands are complex and verbose, don't write paragraphs of documentation to explain them. That's patching a human problem. Instead, write a simple bash wrapper that provides a clear, intuitive API and document that. Keeping your CLAUDE.md as short as possible is a great forcing function for simplifying your codebase and internal tools.
Here's a simplified snapshot:
# Monorepo## Python- Always...- Test with <command>... 10 more...## <Internal CLI Tool>... 10 bullet points focused on 80% use cases...- <Usage example>- Always...- Never <x>, prefer <Y>For <complex usage> or <e> see path/to/<tool>_docs.md...
Finally, we sync this file with an AGENTS.md file to maintain compatibility with other AI IDEs our engineers might use.
Key takeaway : Treat your CLAUDE.md as a high-level, curated collection of guardrails and pointers. Use it to guide where you need to invest in more AI (and human) friendly tools, rather than trying to make it a comprehensive manual.
Context Management
I recommend running /context at least once during a coding session to understand how you're using your 200k token context window (even with Sonnet-1M, I don't trust that the full context window is truly being used effectively). For us, a new session in our monorepo has a base cost of ~20k tokens (10%), leaving 180k for making changes—which can fill up quickly.
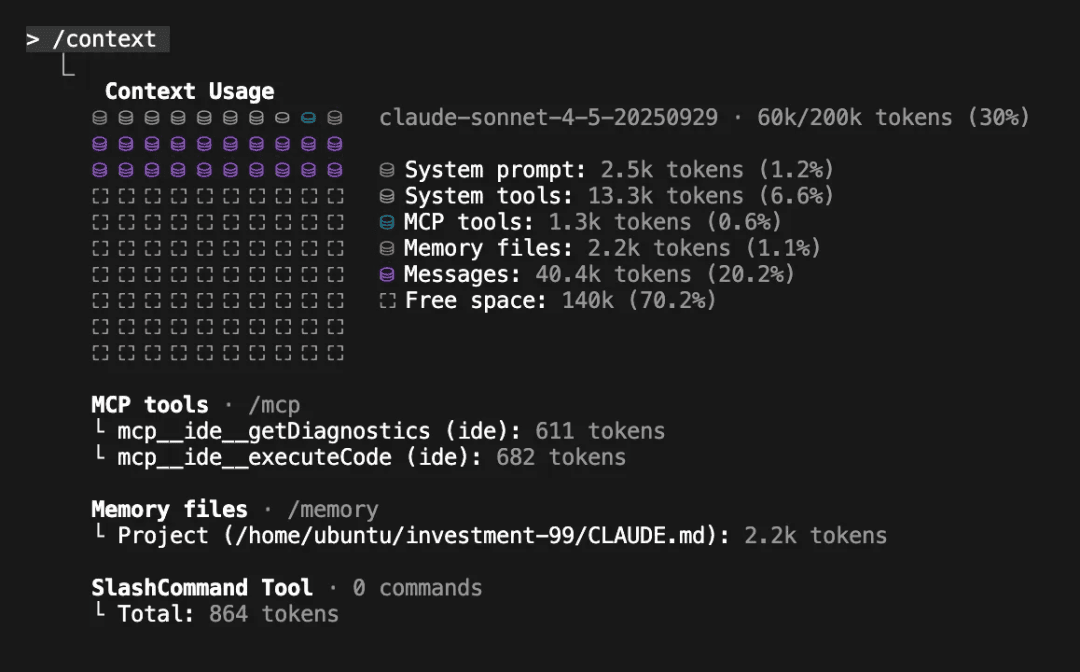
I have three main workflows:
/compact (avoid) : I avoid using it whenever possible. Auto-compression is opaque, error-prone, and poorly optimized.
/clear + /catchup (simple restart) : My default restart method. I /clear state, then run a custom /catchup command that has Claude read all changed files in my git branch.
"Document and clear" (complex restart) : For large tasks. I have Claude dump its plan and progress to a .md file, /clear state, then start a new session by telling it to read the .md and continue.
Key takeaway : Don't trust auto-compression. Use /clear for simple restarts, and use the "document and clear" approach to create persistent external "memory" for complex tasks.
Slash Commands
I view slash commands as simple shortcuts for common prompts, nothing more. My setup is simple:
/catchup : The command I mentioned earlier. It just prompts Claude to read all changed files in my current git branch.
/pr : A simple helper to clean up my code, stage it, and prepare a pull request.
In my opinion, if you have a long list of complex custom slash commands, you've created an anti-pattern. For me, the whole point of an agent like Claude is that you can type almost anything you want and get useful, mergeable results. When you force engineers (or non-engineers) to learn a new list of necessary magic commands documented somewhere to get work done, you've failed.
Key takeaway : Use slash commands as simple personal shortcuts, not as replacements for building more intuitive CLAUDE.md and better tooling for the agent.
Subagents
In theory, custom subagents are Claude Code's most powerful feature for context management. The idea is simple: a complex task requires X tokens of input context (e.g., how to run tests), accumulates Y tokens of working context, and produces a Z token answer. Running N tasks means (X + Y + Z) * N tokens in the main window.
The subagent solution is to outsource the (X + Y) * N work to specialized agents that return only the final Z token answer, keeping the main context clean.
I find them a powerful idea, but in practice, custom subagents create two new problems:
They limit context access : If I create a PythonTests subagent, I've now hidden all test context from the main agent. It can no longer reason holistically about a change. It's now forced to invoke the subagent just to know how to validate its own code.
They enforce human workflows : Worse, they force Claude into a rigid, human-defined workflow. I'm now dictating how it must delegate, which is exactly what I'm trying to have the agent solve for me.
My preferred alternative is to use Claude's built-in Task(...) function to spawn clones of a generic agent.
I put all critical context in CLAUDE.md. Then I let the main agent decide when and how to delegate work to copies of itself. This gives me all the context-saving benefits of subagents without the downsides. The agent dynamically manages its own orchestration.
Session Management
At a simple level, I use claude --resume and claude --continue frequently. They're great for restarting a problematic terminal or quickly resuming old sessions. I often claude --resume sessions from days ago just to have the agent summarize how it overcame a specific error, which I then use to improve our CLAUDE.md and internal tools.
Going deeper, Claude Code stores all session history in ~/.claude/projects/ to leverage raw historical session data. I have scripts that run meta-analysis on these logs, looking for common anomalies, permission requests, and error patterns to help improve agent-facing context.
Key takeaway : Use claude --resume and claude --continue to restart sessions and unearth buried historical context.
Hooks
Hooks are critical. I don't use them in hobby projects, but they're essential for guiding Claude in complex enterprise repositories. They're deterministic "must do" rules that complement the "should do" advice in CLAUDE.md.
We use two types:
Block-on-commit hooks : This is our main strategy. We have a PreToolUse hook that wraps any Bash(git commit) command. It checks for a /tmp/agent-pre-commit-pass file that our test script only creates when all tests pass. If the file is missing, the hook blocks the commit, forcing Claude into a "test and fix" loop until the build succeeds.
Prompt hooks : These are simple, non-blocking hooks that provide "fire and forget" feedback if the agent is doing something suboptimal.
We intentionally don't use "block-on-write" hooks (e.g., on Edit or Write). Blocking the agent mid-plan confuses or even "frustrates" it. It's much more effective to let it finish its work, then check the final completed result at the commit stage.
Key takeaway : Use hooks to enforce state validation at commit time (block-on-commit). Avoid blocking on write—let the agent complete its plan, then check the final result.
Planning Mode
For any "large" feature change in an AI IDE, planning is essential.
For my hobby projects, I just use the built-in planning mode. It's a way to align with Claude before it starts, defining both how to build something and "checkpoints" where it needs to stop and show me its work. Using this feature frequently builds a strong intuition for what minimum context is needed to get a good plan without Claude messing up the implementation.
In our work monorepo, we've started rolling out custom planning tools built on the Claude Code SDK. It's similar to native planning mode, but heavily prompted to align its output with our existing technical design formats. It also enforces our internal best practices out of the box—from code structure to data privacy and security. This lets our engineers "fast plan" a new feature like a senior architect (or at least that's the pitch).
Key takeaway : For complex changes, always use the built-in planning mode to agree on the plan before the agent starts working.
Skills and MCP
If you've been following my posts, you'll know I've moved away from using MCP in most of my development workflows in favor of building simple CLIs (as I argued in "AI Can't Read Your Docs"). My mental model for agent autonomy has evolved into three stages:
Single prompt : Give the agent all context in one big prompt. (Fragile, not scalable).
Tool calling : The "classic" agent model. We handcraft tools and abstract reality for the agent. (Better, but creates new abstractions and context bottlenecks).
Scripting : We give the agent access to the raw environment—binaries, scripts, and documentation—and it writes code on the fly to interact with them.
Given this model, Agent Skills are the obvious next feature. They're the formal productization of the "scripting" layer.
If like me you've been leaning toward CLIs over MCP, you've been implicitly getting the benefits of Skills. SKILL.md files are just a more organized, shareable, and discoverable way to document those CLIs and scripts and expose them to the agent.
Key takeaway : Skills are the right abstraction. They formalize the "scripting"-based agent model, which is more powerful and flexible than the rigid API-like model that MCP represents.
Skills don't mean MCP is dead (see also "Everything Wrong with MCP"). Previously, many people built bad, context-heavy MCPs with dozens of tools that just mirrored REST APIs (read_thing_a(), read_thing_b(), update_thing_c()).
The "scripting" model (now formalized by Skills) is better, but it needs a safe way to access environments. For me, this is MCP's new, more focused role.
MCP shouldn't be a bloated API, but a simple, secure gateway with a few powerful high-level tools:
download_raw_data(filters…)
take_sensitive_gated_action(args…)
execute_code_in_environment_with_state(code…)
In this model, MCP's job isn't to abstract reality for the agent; its job is to manage authentication, networking, and security boundaries, then get out of the way. It provides entry points for the agent, which then uses its scripts and markdown context to do the actual work.
The only MCP I still use is Playwright, which makes sense—it's a complex, stateful environment. All my stateless tools (like Jira, AWS, GitHub) have migrated to simple CLIs.
Key takeaway : Use MCPs that act as data gateways. Give the agent one or two high-level tools (like raw data dump APIs), and it can write scripts against them.
Claude Code SDK
Claude Code isn't just an interactive CLI; it's also a powerful SDK for building entirely new agents—whether for coding tasks or non-coding tasks. I've started using it as my default agent framework for most of my new hobby projects instead of tools like LangChain/CrewAI.
I use it in three main ways:
Large-scale parallel scripting : For large-scale refactors, bug fixes, or migrations, I don't use interactive chat. I write simple bash scripts that call claude -p "in /pathA change all refs from foo to bar" in parallel. This is more scalable and controllable than trying to have the main agent manage dozens of subagent tasks.
Building internal chat tools : The SDK is great for wrapping complex processes in simple chat interfaces for non-technical users. Like an installer that falls back to Claude Code SDK to fix problems for users when things go wrong. Or an internal "v0-at-home" tool that lets our design team quickly code mock frontends in our internal UI framework, ensuring their ideas are high-fidelity and code is more directly usable in frontend production code.
Rapid agent prototyping : This is my most common use. It's not just for coding. If I have an idea for any agent task (e.g., a "threat investigation agent" using custom CLI or MCP), I use Claude Code SDK to quickly build and test prototypes before investing in full deployment scaffolding.
Key takeaway : Claude Code SDK is a powerful general-purpose agent framework. Use it for batch code, building internal tools, and quickly prototyping new agents before using more complex frameworks.
GitHub Actions
The Claude Code GitHub Action (GHA) is probably one of my favorite and most underrated features. It's a simple concept: just run Claude Code in GHA. But that simplicity is exactly what makes it so powerful.
It's similar to Cursor's background agent or Codex's hosted web UI, but more customizable. You control the entire container and environment, giving you more data access and, more importantly, stronger sandbox and audit controls than any other product offers. Plus, it supports all advanced features like Hooks and MCP.
We use it to build custom "create PR from anywhere" tools. Users can trigger PRs from Slack, Jira, or even CloudWatch alerts, and GHA will fix bugs or add features and return a fully tested PR.
Since GHA logs are complete agent logs, we have an operational process to regularly review these logs at the company level, looking for common errors, bash errors, or inconsistent engineering practices. This creates a data-driven flywheel: errors -> improve CLAUDE.md / CLI -> better agents.
$ query-claude-gha-logs --since 5d | claude -p "Look at where other claudes got stuck and fix it, then submit a PR"
Key takeaway : GHA is the ultimate way to operationalize Claude Code. It transforms it from a personal tool into a core, auditable, and self-improving part of your engineering system.
settings.json
Finally, I have some specific settings.json configurations that I find essential for both hobby and professional work.
HTTPS_PROXY/HTTP_PROXY : Useful for debugging. I use it to inspect raw traffic to see exactly what prompts Claude is sending. For background agents, it's also a powerful tool for fine-grained network sandboxing.
MCP_TOOL_TIMEOUT/BASH_MAX_TIMEOUT_MS : I raise these. I like running long, complex commands, and default timeouts are often too conservative. I'm honestly not sure if this is still needed now that bash background tasks exist, but I keep it just in case.
ANTHROPIC_API_KEY : At work, we use enterprise API keys (via apiKeyHelper). It moves us from "per-seat" licensing to "usage-based" pricing, which is a much better model for how we work.
It accounts for the huge variance in developer usage (we see 1:100x differences between engineers).
It lets engineers experiment with non-Claude-Code LLM scripts, all under our single enterprise account.
"permissions" : I occasionally self-audit the list of commands I allow Claude to auto-run.
Key takeaway : Your settings.json is a powerful place for advanced customization.
Conclusion
That's a lot of content, but hopefully you found it useful. If you're not using CLI-based agents like Claude Code or Codex CLI yet, you probably should. There are few good guides for these advanced features, so the only way to learn is to dive in.
https://blog.sshh.io/p/how-i-use-every-claude-code-feature[1]
References
[1] https://blog.sshh.io/p/how-i-use-every-claude-code-feature: https://blog.sshh.io/p/how-i-use-every-claude-code-feature